大数据平台架构大全
- 大数据
- 2024-06-24 17:24:06
- 1243
随着互联网的发展,互联网上充斥着越来越多的信息,而大数据就是在对这些信息的收集、分类和汇总的基础上,对必要的信息进行分类,并利用这些信息来完成一些信息。 工作需要能力技术。
今天火影电脑培训我们主要来说分析大数据技术水平。
移动互联网时代,数据量呈指数级增长,其中85%以上是文本、音频、视频等非结构化数据.占据.而且未来还会变得更大。 Hadoop架构的分布式文件系统、分布式数据库和分布式并行计算技术解决了存储、管理和处理大规模、多源、异构数据的挑战。
自2006年4月发布第一个ApacheHadoop版本以来,Hadoop已成为大规模数据存储、管理和计算的开源工具。 技术,在v2.7.2稳定版本中,其组件也是一个庞大的三驾马车,由来自传统三驾马车HDFS、MapReduce、HBase社区的60多个相关组件组成,包括数据存储、执行引擎、编程和数据访问框架等。 已经发展成为一个生态系统。 该生态系统已经从1.0版本的三层架构发展到目前的四层架构。
底层——存储层
互联网数据量达到PB级。 如今,传统的存储方式已经不能满足高效的IO性能和成本的要求,Hadoop的分布式数据存储和管理技术解决了这个问题。 HDFS现在是大数据磁盘存储事实上的标准,并且正在与越来越多的文件格式包(Parquent等)分层。 未来,HDFS将继续扩大对新存储介质和服务器架构的支持。 另一方面,与常用的Tachyon和Ignite不同,新兴的分布式内存文件系统Arrow提供了基于列的内存存储处理和交互的规范,并得到了许多开发人员和行业巨头的支持。
与传统关系数据库不同,HBase非常适合非结构化数据存储。 Kudu是Cloudera于2023年10月推出的分布式关系数据库,预计将成为下一代分析平台的关键组件,使Hadoop市场更加接近传统数据仓库市场。
中间层-管理层和控制层
管理层和控制层图层运行高效。 Hadoop集群资源和数据管理的可靠运行。 YARN诞生于MapReduce1.0,现已成为Hadoop2.0的通用资源管理平台。 如何与容器技术深度融合,提升调度、细粒度控制、多租户支持等能力,是YARN需要进一步解决的问题。 另一方面,Hortonworks的Ranger、Cloudera的Sentry和RecordService组件在数据级别实现安全控制。

上一篇:大数据平台拓扑图
下一篇:现有的大数据平台架构










热门文章

物联网概论重点知识
2024-06-25 11:42:24
物联网哪个专业最好就业
2024-06-26 10:30:24
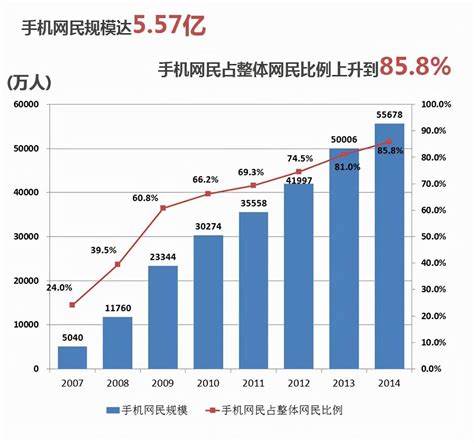
交通大数据应用前景
2024-06-17 16:38:09
大数据在智慧交通中有哪些应用
2024-06-23 12:43:39
大数据与云计算开启了什么时代
2024-06-20 15:35:02
大数据的服务模式有哪些
2024-06-25 14:06:13
移动互联网之前是什么互联网
2024-06-23 12:59:08
大数据it行业术语
2024-06-16 16:02:25
物联网模块怎么使用
2024-06-26 15:42:49
计算机物联网专业就业方向
2024-06-18 15:36:44