大数据架构如何实现的
- 大数据
- 2024-06-17 14:58:25
- 7642
专业角度介绍大数据架构实现
大数据架构的实现是一个复杂的过程,涉及多个技术领域和专业知识。 以下是一些关键方面:
1. 数据采集与处理:
数据源识别: 识别所有潜在的数据源,并根据数据类型、格式、质量等因素进行分类。
数据提取: 利用各种工具和技术从数据源中提取数据,例如 ETL 工具、API、爬虫等。
数据清洗: 对数据进行清洗,去除错误、缺失值、重复项等,确保数据的质量和完整性。
数据转换: 将数据转换成适合分析的格式,例如将文本数据转换成数值型数据。
2. 数据存储与管理:
分布式存储系统: 使用分布式存储系统(如 Hadoop HDFS、云存储等)存储海量数据,并提供高可用性和可扩展性。
数据仓库: 构建数据仓库,将清洗后的数据进行整合、分析和展现,方便用户进行数据挖掘和商业分析。
数据模型设计: 设计合适的数据库模型,以满足不同的分析需求。
数据备份与恢复: 制定数据备份策略,定期备份数据,确保数据安全。
3. 数据分析与挖掘:
数据分析工具: 使用各种数据分析工具,例如 SQL、MapReduce、Spark、机器学习等,对数据进行分析和挖掘。
数据可视化: 使用各种可视化工具,将分析结果以图表、图形等形式展现,方便用户理解和决策。
算法选择与优化: 根据实际需求选择合适的算法,并对算法进行优化,提升分析效率。
4. 数据安全与隐私保护:
数据加密: 对敏感数据进行加密,防止数据泄露。
访问控制: 制定严格的访问控制策略,限制用户的访问权限。
数据脱敏: 对敏感数据进行脱敏处理,保护个人隐私。
5. 架构设计与优化:
可扩展性: 设计可扩展的架构,以应对不断增长的数据量和用户需求。
高可用性: 确保系统的高可用性,防止系统故障影响数据处理。
性能优化: 对系统进行性能优化,提升数据处理效率。
6. 技术选择与集成:
选择合适的技术: 根据实际需求选择合适的技术,例如 Hadoop、Spark、Kafka、Cassandra等。
技术集成: 将不同的技术进行集成,构建完整的架构。
7. 运维与管理:
监控与维护: 对系统进行实时监控,及时发现问题并进行维护。
性能调优: 根据实际情况对系统进行性能调优。
安全管理: 定期进行安全检查,修复漏洞,确保系统安全。
总之,大数据架构的实现需要综合考虑多个方面,并根据实际需求进行灵活的设计和优化。









热门文章

物联网应用设计题目
2024-06-18 12:27:32
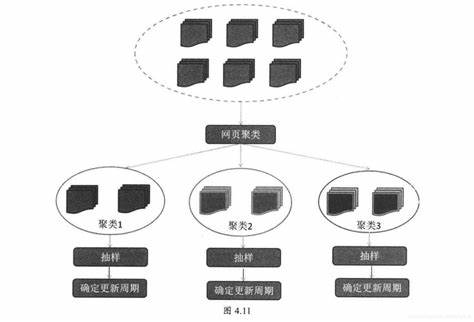
大数据架构设计示意图
2024-06-17 17:37:59
新能源网约车车型一览表
2024-06-17 11:08:50
北森云计算公司招聘
2024-06-16 13:14:10
5g工业互联网512工程
2024-06-17 17:43:55
互联网是一片净土什么梗
2024-06-17 11:05:07
互联网高级营销师证书有什么用
2024-06-18 13:49:53
互联网是一片净土是谁说的
2024-06-16 17:55:11
手机显示无法访问互联网怎样处理
2024-06-17 17:04:11
互联网电信资费套餐一览表
2024-06-16 10:05:58